JDK1.8的hashMap采用数组+链表+红黑树的结构,jdk1.7的hashMap采用数组+链表的结构,红黑树的目的是为了解决过长链表效率低的问题。JDK1.8修改了扩容机制,扩容时不需要计算hash,这个在后文会详细说明。
HashMap有几个重要的成员变量,见下表:
| 变量 | 含义 |
|---|---|
| initialCapacity | HashMap容量 |
| loadFactory | 负载因子 |
| threadshold | 扩容阈值,capacity*loadFactory |
| modCount | 修改次数,用于并发时判断数据是否过期(CAS) |
通过调节负载因子,可使 HashMap 时间和空间复杂度上有不同的表现。
- 调低负载因子时,HashMap 所能容纳的键值对数量变少。扩容时,重新将键值对存储新的桶数组里,键的键之间产生的碰撞会下降,链表长度变短。此时,HashMap 的增删改查等操作的效率将会变高,这里是典型的拿空间换时间。
- 增加负载因子(负载因子可以大于1),HashMap 所能容纳的键值对数量变多,空间利用率高,但碰撞率也高。这意味着链表长度变长,效率也随之降低,这种情况是拿时间换空间。至于负载因子怎么调节,这个看使用场景了。一般情况下,用默认值就可以了
计算哈希
hashMap的所有操作都离不开hash值的计算,因此,有必要将hash值的计算写在前面。
1 | static final int hash(Object key) { |
从源码可以看出,hash值的计算是由key的hashCode进行位运算后得到的,在Java中,hash是int型,32位,前16位为高位,后16位为低位,先取hash的低位,和高位进行异或运算,得到hash值,位运算如下图:

这么做的好处就是最大限度的发挥高位和低位的作用,提高hash值的复杂度(当我们覆写hashCode方法时,有可能会写出分布性不佳的hashCode方法)。
计算一个键值对在数组中的下标时,采用了公式:(n-1) & hash,n为数组容量,n-1与hash值进行与运算,等价于hash%n,往往只有低位参与了计算,因此,hashMap在计算key的hash值进行的位运算,有利于hash值的高位与低位均可以参与到计算数组下标中去,这就是为什么不直接使用key.hashCode()的原因。
为什么说N-1 & hash 等价于 hash%N
N总是2的n次幂,即只有一位为1,N-1的后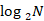 位全部为1(此处不明白的可以查看2.4.3节的表2.1《数组容量与二进制值》),N-1 & hash 即hash的后位为1的位组成的值,它正是hash%N的余数,如下图:
位全部为1(此处不明白的可以查看2.4.3节的表2.1《数组容量与二进制值》),N-1 & hash 即hash的后位为1的位组成的值,它正是hash%N的余数,如下图:

put
先定位要插入的键值对属于哪个桶,定位到桶后,再判断桶是否为空。如果为空,则将键值对存入即可。如果不为空,则需将键值对放置于链表最后一个位置或插入红黑树中,或者覆盖键完全相同的值。最后,以put后的容量对比threadshold决定是否需要扩容。
1 | 1 public V put(K key, V value) { |
上述代码块的核心逻辑是:
- 1)数组table是否为空?为空则通过扩容的方式初始化
- 2)要插入的键是否与桶中第一个节点的键是同一个(equals)?若是,则标记该节点并进行第4步,若不是,则遍历树或链表。
- 3 ) 遍历树或链表,待插入的键是否已存在?若存在,则标记该节点进行第4步,若不存在,则插入链表的尾节点或红黑树对应节点。
- 4)上述3步已完成了带插入节点e的定位,根据onlyIfAbsent判断是否用新值覆盖旧值
- 5)最后,根据键值对数量与threadshold的比较,判断是否需要进行扩容
get
hashMap查找操作比插入操作更简单,源码如下:
1 | public V get(Object key) { |
扩容机制
在调用put方法将元素插入后,会判断是否超出负载因子*容量,超出后便调用resize()方法进行扩容。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过(数组大小*loadFactor)时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过160.75=12的时候,就把数组的大小扩展为216=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作
JDK1.7的扩容
JDK1.7版本的HashMap是数组+链表的结构
扩容机制:新生成一个数组,然后拷贝旧数组里面的每一个数组元素表示的链表(Entry)到新数组里面
1 | void resize(int newCapacity) { |
假设有下面的数组大小为2,loadFactory为默认值0.75的HashMap,在插入第二个元素后(key = 5)会进行扩容,扩容的新数组大小为4(假设hash的计算方法是key%数组大小)
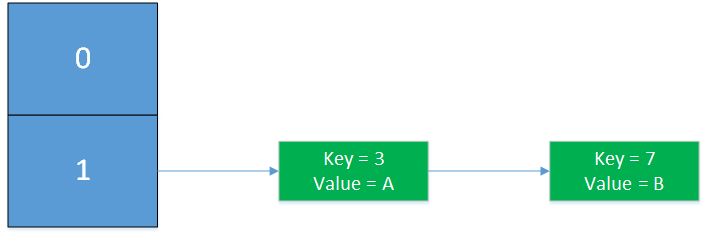
创建新数组,假设hash的计算方法是key%数组大小,那么key为3和7的Entry均应落在新数组下标为3的位置,即newTable[i]的i为3。此时进入while(null != e)开始遍历旧数组下标为1的Entry
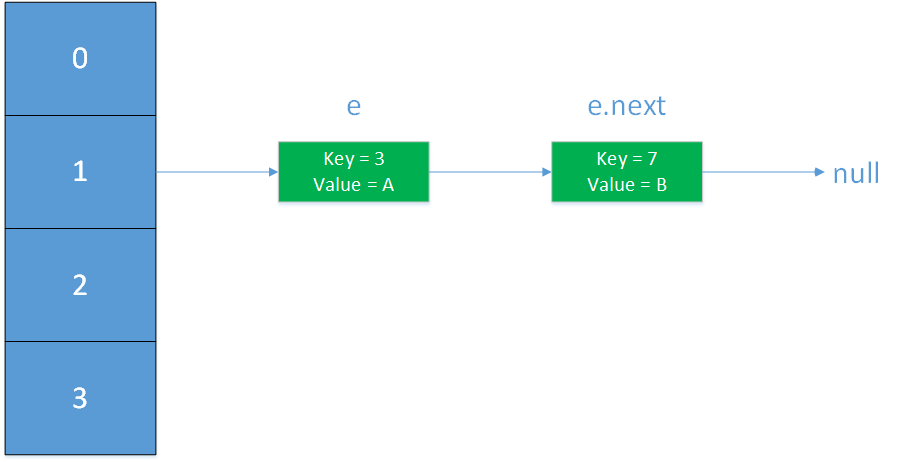
执行newTable[i] = e,将e插入newTable[3]对应的链表的头部
执行e=next,此处的next存放的是旧的e.next,即上图中e.next(key=7), 将e置为key的7的元素。
经过上述三步,HashMap处于下图的状态,记为resize第二阶段完成:
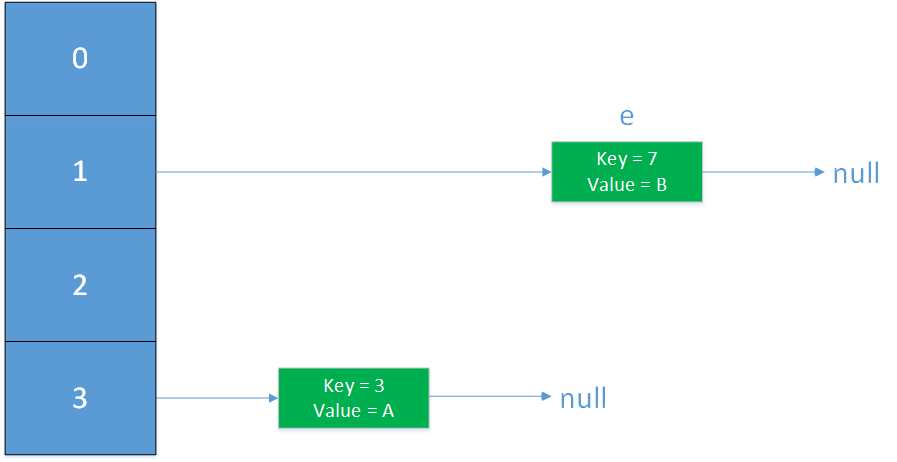
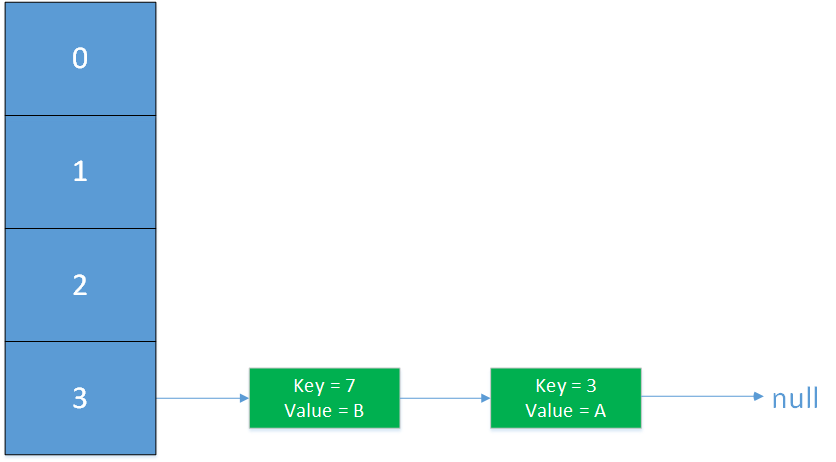
为了便于理解,将transfer简化,只留下关键步骤:假设两个线程同时执行put操作,进入了transfer环节。
1 | 0 while(null != e) { |
代码块的注释是按照时间顺序的,在第3行线程1将newTable[3]的赋值为key为3的Entry后(未执行e=next),线程1的状态如下;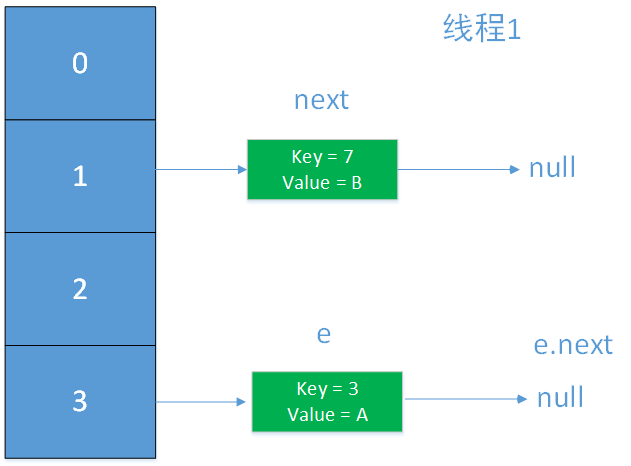
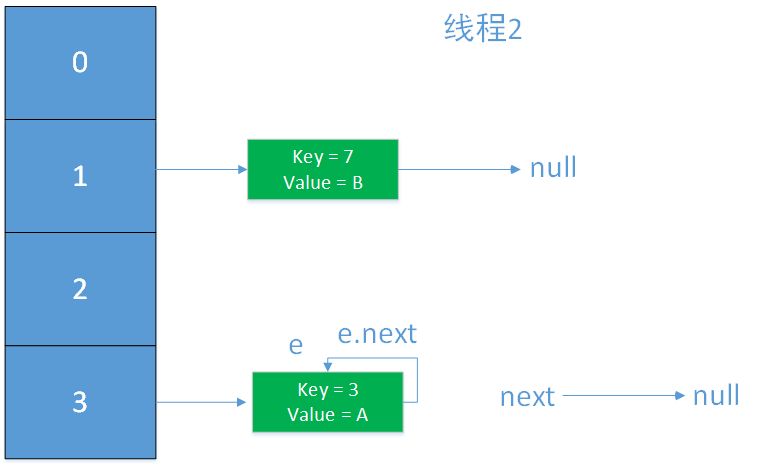
然后,线程2执行最后一步,e = next,发现e = null不满足while条件,跳出循环,此时,并没有出现死循环的问题,现在的问题仅仅是链表出现了闭环。
待下一次扩容时,才会出现死循环的问题,e.next永远为e,再也无法跳出循环。
上述只是链表闭环的一种情况,而且是简化版,实际情况过多,逐个赘述没有意义,不再赘述,重点是需要了解到多线程put时出现resize,可能会导致链表闭环,从而CPU占用率达到100%。
JDK1.8的扩容
在JAVA 8版本,HashMap改进了扩容的方式,不再使用JDK 1.7的头部插入法。
为了便于理解,只摘取源码中扩容相关的核心代码:一个for循环用于将旧的数组每个元素e迁移至新数组中。
- 如果
e.next == null,表示旧数组中该位置没有哈希碰撞,直接计算e在新数组中的位置并赋值 - 如果e是TreeNode的实例,计算在新数组的下标,并添加到新数组对应位置的红黑树中,先不赘述
- e是链表,按照链表的逻辑插入,本节主要介绍链表情况下的插入,用以比较与JDK1.7的不同。
1 | 1 for (int j = 0; j < oldCap; ++j) { |
e是链表的情况下,声明了loHead、loTail、hiHead、hiTail,他们分别是lo和hi链表的头结点与尾节点。lo链表会插入与旧数组相同的下标处newTab[j] = loHead,hi链表插入旧下标偏移旧容量处newTab[j+oldCap] = hiHead。
上述代码块都很好理解,建立了两个链表,依次在末端插入新的元素,在多线程环境下,JDK 1.7由于头部插入法导致了链表闭环,JDK 1.8采用尾部插入法,有效的避免了JDK1.7链表闭环的问题。但是
- 没有解决JDK1.7中的数据丢失的问题,比如多个线程同时put的时候,当index相同而又同时达到链表的末尾时,另一个线程put的数据会把之前线程put的数据覆盖掉,就会产生数据丢失。
- 多线程下操作同一对象时,对象内部属性的不一致性还会导致死循环
不过,HashMap本来就不是为多线程环境设计的,多线程应该使用ConcurrentHashMap。
现在把目光放在上述代码块第15行的if ((e.hash & oldCap) == 0),它用来判断元素放置在lo链表还是hi链表,这两个链表分别插入在数组下标为旧下标newTab[j]和旧下标+旧容量处newTab[j+oldCap]。上述代码块的第一个注释为如果e后面没有元素,说明没有哈希碰撞,直接赋值,此处将e放置在了newTab[e.hash & (newCap - 1)]处。而在前面介绍的put方法中,也出现了tab[(n - 1) & hash],我们发现总是将n-1、hash进行与操作(&),n表示数组容量,它总是2的n次幂,n的二进制如下:
数组容量N的二进制值总是只有1位为1,其他位全是0,对于N-1的二进制,后位全部为1,将位记为标记位M,那么对于2N-1的二进制,它的标记位为M+1。(n-1)&hash实际上就是hash%(n-1),只不过JDK1.8采用了速度更快的位运算。
根据HashMap的数据散落原理,是取hash值然后对数组的大小取余,且每次扩容后,容量为扩容前的二倍,那么将旧数组容量oldCap记为N:
e.hash &(N-1) = oldPos // 标记位为M
e.hash & (2N-1) = newPos // 标记位为M+1
它们等价于:
e.hash & 0000 0111…. = oldPos // M个1
e.hash & 0000 1111…. = newPos // M+1 个1
上述两个式子分别用来计算e在新旧数组中的位置newPos、oldPos,它们实际上是e.hash对一个低位全部为1,高位全部为0的二进制的与运算,所以在计算Position时,e.hash比标记位更高的位是无意义的,这个标记位取决于数组的容量大小:
- 对于旧的数组,容量N、标记位M,只考虑e.hash的低M位。
- 对于新的数组,容量2N、标记位M+1,只考虑e.hash的低M+1位。
现在来看if ((e.hash & oldCap) == 0)的意义:
e.hash & N = 0 ==> e.hash & 0000…01000 = 0
N的二进制中唯一的1出现在标记位M+1处,即oldCap的唯一的1出现在此处,所以这个if语句用来判断e的hash值的倒数M+1位是否为0:
如果e.hash倒数第M+1位为0,有下面三个式子:
e.hash & 0000 0111…. = oldPos // M个1
e.hash & 0000 1111…. = newPos // M+1 个1
e.hash & 0000 1000…..= 0
因此,newPos = e.hash & 0000 1111… = e.hash & 0000 0111…. =oldPos
只考虑e.hash的低M位,与旧数组中位置计算方式一样,得到的结果也必然相同,所以e在新旧数组中位置相同。
如果 e.hash倒数第M+1位不为0(为1),则有下面的三个式子:
e.hash & 0000 0111…. = oldPos // M个1
e.hash & 0000 1111…. = newPos // M+1 个1
e.hash & 0000 1000…..= 000..10000 // 倒数第M+1位为1
因此,newPos = e.hash & 0000 1111… = (e.hash & 0000 0111….)+ (e.hash & 0000 1000…..) = oldPos + oldCap
通过以上的位运算,不需要再重新计算hash值,即可完成旧数组向新数组的迁移,大大地提高了效率
equals和hashCode
equals
Object的equals比较的是对象的内存地址。源码如下:
1 | public boolean equals(Object obj) { |
而在实际的业务中,往往判断两个对象是否equals时,是根据对象所对应的“值”去判断的,这时,就需要重写equals方法。比如JDK的String类。
1 | public boolean equals(Object anObject) { |
hashcode
java.lang.Object中对hashCode的约定:如果两个对象根据equals方法比较是相等的,那么调用这两个对象的任意一个hashcode方法都必须产生相同的结果。比如String类,因为重写了equals,那么必须重写hashcode。
首先看Object的hashcode的计算方式(参考博客),下面的代码为openjdk1.8的Native源码。
1 | static inline intptr_t get_next_hash(Thread * Self, oop obj) { |
JDK1.8默认采用的是最后一个else语句中的计算方式xor-shift算法,该算法根据四个初始值可以生成一系列随机数。
1 | // xor-shift 伪随机数生成算法 |
其中,hashStateX计算方式为hashStateX=Slef->os::random(),hashStateY、hashStateZ、hashStateW都是固定初始值,最终的Value由这四个值计算得出。
在第一个if语句if(hashCode==0)中有一行注释: so it’s possible for two threads to race and generate the same RNG,说明了两个线程竞争调用os::random()时有可能产生相同的随机数,这个是我们不想看到的,因此,JDK采用了xor-shift算法,即便初始值相同,产生的随机数也不同,有效的规避了这种情况,最终产生的随机数是线程相关的,支持多线程并发,有可能是目前最好的hashCode算法。(最后一个else语句中的注释:Marsaglia’s xor-shift scheme with thread-specific state This is probably the best overall implementation )
总之,默认地,Object.hashCode()产生一个线程安全的唯一随机值,可以通过在JVM启动参数中添加-XX:hashCode=2,改变默认的hashCode计算方式,JVM参数里的hashCode为0时hashCode的计算方式是os随机值,多线程竞争时可能会出现重复,为1时是对象的内存地址做位移运算后与一个随机数进行异或得到的结果,为2时是固定值、为3时是自增值
再看String类的hashcode方法,String对象的hash值与每个字符都有关,所以该hash值更看重的是业务层面的“值”的比较。这也对应了重写了equals,那么必须重写hashcode的约定。
1 | public int hashCode() { |
使用重写过equals()和hashcode()的对象作为Map的键
在使用hashMap时,判断是不是同一个键的条件如下,为true时表示同一个键
1 | if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) |
对于第一个条件:比较的是Node的hash值,它通过构造方法设置:
1 | // Node的hash值通过构造方法设置 |
以put为例,调用过程如下,可以看出,Node的hash值等于key的hash值
1 | public V put(K key, V value) { |
因此,满足下面任一个条件即视为同一个键:
- key的hash值相同且key为同一个(==表示指向同一个堆地址,是同一个对象)
- 两个键满足equals
对于第一个条件,与key的hash值完全相关,前面介绍了JDK1.8hash值默认是一个线程相关的随机数,而在业务层面上,往往键都是有实际意义的,因此,尽量不要使用JDK的随机数作为对象的hash值。如果不注意,将没有重写hashCode()的对象作为了Map的Key,在调用get、put、remove方法时,可能会出现一些意外的错误,比如,你不想让两个键相同(这里的相同指的是值相同,业务意义相同,比如人名、身份证ID)的对象同时出现在Map中,那么,有必要重写hashCode,否则会出现冲突,例子如下:。
1 | class Person { |
上面的例子中,你本来不想让姓名重复的用户插入到Map中,但是因为没有重写Person的hashCode,导致这两个对象tom、tom2的hashCode不同,都成功插入Map。
对于第二个条件,Object.equals()比较的是键的内存地址,这也与业务无关。示例可参考上面的示例。
因此,尽量使用那些已经覆写了equals和hashCode的类,比如String、Integer等,如果要使用自定义的类作为hashMap的key,要覆写equals和hashCode方法,将它改为值的判断,避免使用时出现意外的错误。
细节疑问
为什么HashMap实现了Serializable接口,却将table声明为transient?(声明为transient,不会被序列化)
答:参考StackOverfolw回答,HashMap使用wirteObject、readObject实现自定义的序列化和反序列化,序列化时记录了的table的size、键值对的size、以及所有的key-value映射,没有序列化table(Node数组),Node包含了hash值、key、value、以及下一个Node指针,Node的作用是便于遍历键值对,table不序列化的目的只是为了节省空间,当反序列化的时候,通过readObject重新构建table。
为什么链表长度为8时进行树化,怎么不是2、4、16、32?
红黑树占据的空间是链表的两倍,删除和新增数据都需要调整树,所以会尽量避免使用红黑树,在hashMap源码196行的有一段注释提到:当选择计算hash值的算法足够好时,数据均匀分布,呈现泊松状,同一个桶中的节点数等于8的概率为亿分之6,因此,为8时链表转换为红黑树的概率已经极低了。
- 一个桶中链表长度达到4的概率为1.5%,此时链表查询复杂度为4,红黑树为2,差距不大
- 一个桶中链表长度为8的概率为亿分之6,此时链表复杂度为8,红黑树为3,差距开始明显,有必要树化
- 一个桶中长度为16的概率更低,除非你重写的hashCode方法真的很烂,此时链表复杂度为16,红黑树为4,差距较大,树化已经晚了
为什么是树的节点数是6的时候,退化成链表,怎么不是8?
如果是8,或者7,假如有大量的操作在长度7和8之间来回切换,这种结构的变换导致耗时更多,所以用6进行一个过渡。