副本集
副本集是一组服务器,其中有一个主服务器(primary),用于处理客户端请求,还有多个备用服务器(secondary),用于保存主服务器的数据副本,如果主服务器崩溃了,备份服务器会自动选举出一个新的主服务器。
一般的,只有主服务器才会用作写操作,备用服务器最多支持读操作,甚至读写均不支持,只用来做备份。
大多数
副本集中有一个很重要的概念是”大多数“,选择主节点时由”大多数“决定,主节点只有在得到”大多数“支持时才能继续作为主节点,这里的”大多数“被定义为副本集中一半以上的成员。它是动态变化的,如果某一个节点挂了,那么”大多数“就有可能发送变化,举个例子:
| 副本集的成员总数 | ”大多数“ |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 4 |
| 7 | 4 |
$$
“大多数” >= (总数+1)/2
$$
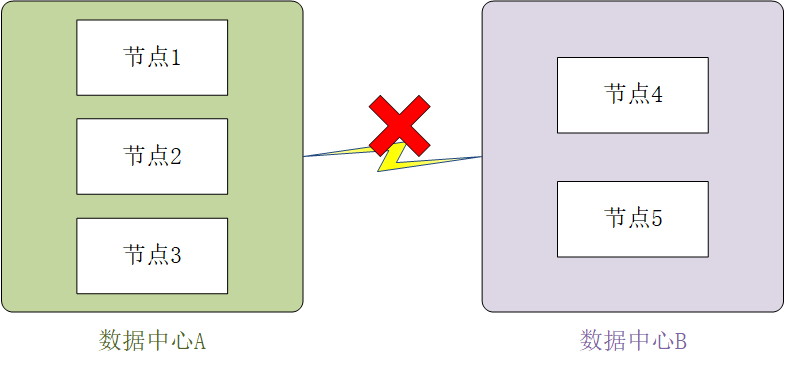
下图是一个包含5个节点的副本集,其中3个位于数据中心A,另外2个位于数据中心B,如果节点1、2、3全挂了,节点4、5不能选举出主节点。这种规定是有目的的:
对于节点4、5而言,节点1、2、3全挂掉与下图情况(数据中心A与B之间的链路中断了)完全相同,此时,数据中心A中还有3个可用节点,满足”大多数“,会选举出一个主节点,数据中心B只有两个可用节点,如果允许数据中心B选举出主节点,那么会出现两个主节点,这就是为什么一定要保证”大多数“的原因,时刻保证只有一个主节点可用,避免多个主节点写入出现冲突所导致的开发的复杂性。
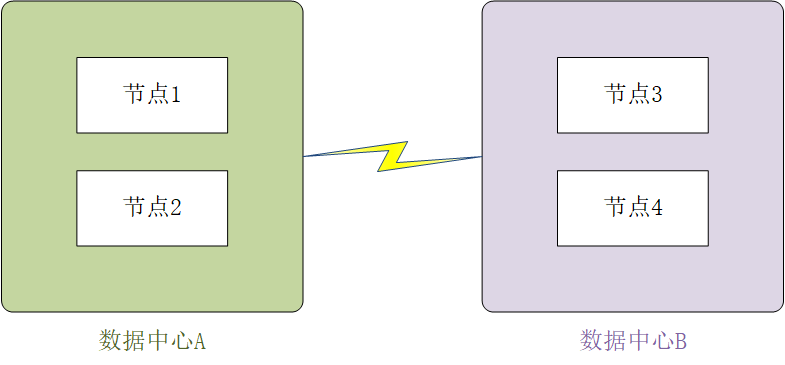
还有另外一种情况,同样是两个数据中心,A与B的节点数完全相等,A与B链路断开时,任何一边都无法满足”大多数“。为避免这种情况,有两种做法:
- 将大多数放在同一个数据中心,如节点1、2、3放置在中心A,节点4放在中心B,这样做很简单,但是还会遇到上面的问题,节点1、2全部挂掉了,节点3、4无法提供服务
- 添加一个仲裁节点,只用来做仲裁,不用来做备份,放置在数据中心C,这样任何一个数据中心的服务器都可以满足”大多数“的条件,这样做的缺点是:将服务器分布到三个地方。
选举机制
当一个备份节点A无法与主节点连通时,它就会请求其他的副本集成员将自己选举为主节点。其他副本集成员会进行以下检查:
- 自身能否与主节点连通
- 通过比较A的oplog与自身的oplog,确定A节点的数据是否最新
- 是否有其他优先级更高的节点请求被选举为主节点
赞成票的权重为1,反对票的权重为-10000,所以即使”大多数“成员中只有一个否决了本次选举,选举就会取消。选举的过程一般只需要几毫秒,实际情况可能会遇到网络问题、服务器过载导致响应慢、选举打成平局,平局后每个成员需要等待30s才能进行下一轮选举,所以,如果有太多错误发生的话,选举可能需要几分钟。
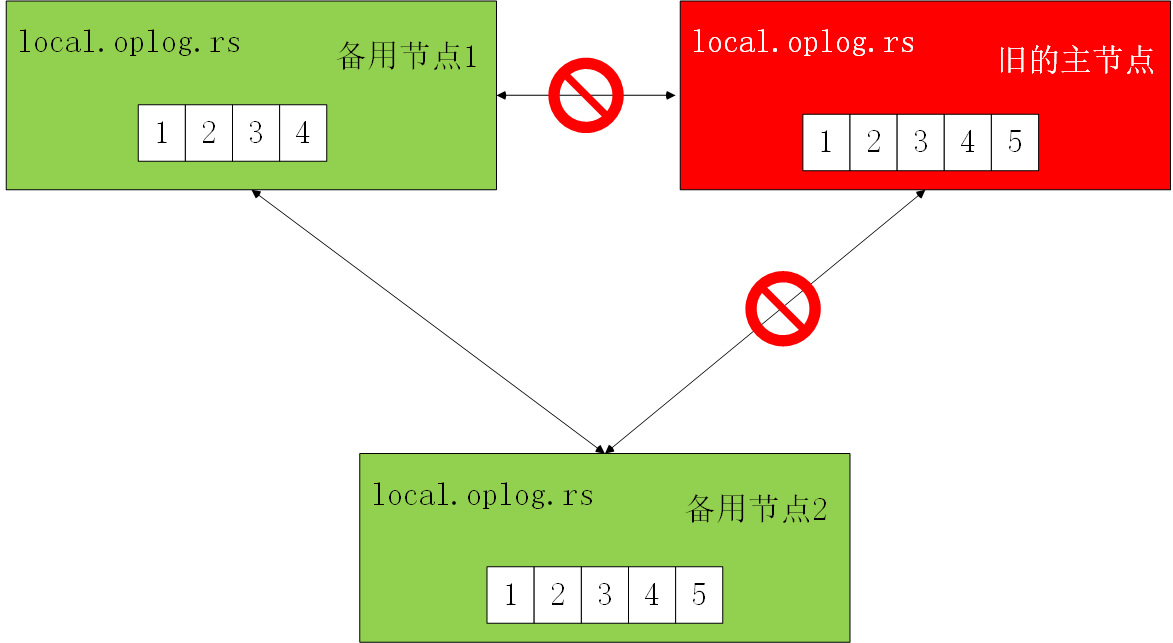
首先关注第二点,确定被选举人的数据是否是最新的。如下图所示,一共有3个节点,主节点网络故障,备用节点1发现主节点无法连通,向备用节点2请求选举自身为主节点,备用节点2首先检查到主节点无法连通,然后将对比备用节点1的local.oplog.rs与自身的local.oplog.rs数据,发现备用节点1的oplog中没有记录自身的最新写操作5,投出反对票。此时,备用节点1获悉自身数据不是最新的,会向备用节点2请求最新的oplog,然后再次请求选举为主节点,新一轮的选举中,之前投否决票的的可以重新投票;同时,备用节点2也可以向备用节点1发起请求,请求被选举为主节点。最终,只要备用节点1与备用节点2之间保持连通的状态,一定能选举出新的主节点。
上面描述的是备用节点1和备用节点2相等时的情况,假如备用节点1和备用节点2已经选举出新的主节点—备用节点1。运行一段时间后,使用下面的命令新添加一个节点,称之为节点3,节点3此时没有任何数据,会从新的主节点(之前的备用节点1)获取最新的oplog,数据更新到最新后,新的主节点(之前的备用节点1)检测到节点3为高优先级节点,新的主节点(之前的备用节点1)主动退位,重新进行选举,直到选举节点3为主节点为止。
1 | rs.add({"_id":4, "host":"172.28.70.1:27017", "priority":1.5}) |
让主节点永远保持最新的oplog是非常重要的,因此,所有的写操作都在主节点进行,在对读取数据一致性要求不高或希望主节点挂掉仍能读数据的场景下,备用节点可以分担主节点读操作的压力。
通过设置readPreference=secondaryPreferred将读请求设置路由至备用节点,建立索引会消耗内存和硬盘空间、降低写操作性能,为进一步缓解主节点压力,
- 可以设置一个与主节拥有不同索引的备份节点
- 也可以使驱动程序创建一个直接连接到目标备用节点用作读操作(而不是连接到整个副本集)
- 甚至部分数据从主节点读另一部分从备用节点读。
心跳
每个节点都需要知道其他成员的状态,用来确定下列信息:
- 哪个是主节点
- 哪个挂掉了
- 是否满足”大多数”
- 是否有比主节点优先级更高的节点
为了维护集合的最新视图,每个成员每隔2s就会向其他成员发送一次心跳,心跳请求的信息量非常小,用来检查每个成员的状态,获取简要信息。
节点状态
- STARTUP 节点刚刚启动,还未加载副本集配置
- STARTUP2 节点加载副本集配置,进行初始化同步
- RECOVERING 初始化完成,进行检查以确保自身处于有效状态,当节点与其他节点脱节时,也会进入该状态,这时,这个成员处于无效状态,需要重更新同步(不是初始化同步,不过于初始化同步动作是一样的,都是同步oplog),同步完成后,回到正常状态(主节点状态、备份节点状态)
- PRIMARY 主节点正常运行的状态
- SECONDARY 备份节点正常运行的状态
- ARBITER 在正常操作中,仲裁节点始终处于该状态,仲裁节点没有oplog,没有数据
- DOWN 节点无法连通
- UNKNOW 所有的节点都无法连通该节点
- REMOVED 节点被踢出副本集
- ROLLBACK 回滚,主节点执行一个写操作后挂掉了,备份节点没有复制该操作,新的主节点也会漏掉该操作,旧的主节点重新上线后,会回滚该操作,然后重新同步。
- FATAL 节点发生不可挽回的错误,也不再尝试恢复正常,这是应该重启该节点、重新同步。
分片
分片(sharding)是指将数据拆分,将其分散在不同的机器上的过程。分片可以分为:
- 手动分片(manual sharding)
- 自动分片(autosharing)
几乎所有的数据库都支持手动分片,应用维护与各个服务器之间的连接,每个连接是完全独立的,由应用管理数据的路由规则,这种方式的缺点是:难以维护、向集群新增节点或删除节点都很麻烦、调整分布以及负载模式也不轻松,因此,MongoDB提供了自动分片机制。
基于Mongos的自动分片
MongoDB支持自动分片,使得数据库架构对应用不可见,对于应用而言,好像始终在使用一台单机的MongoDB服务器一样,同时,MongoDB自动处理数据在分片上的分布,也更加容易新增或删除节点。
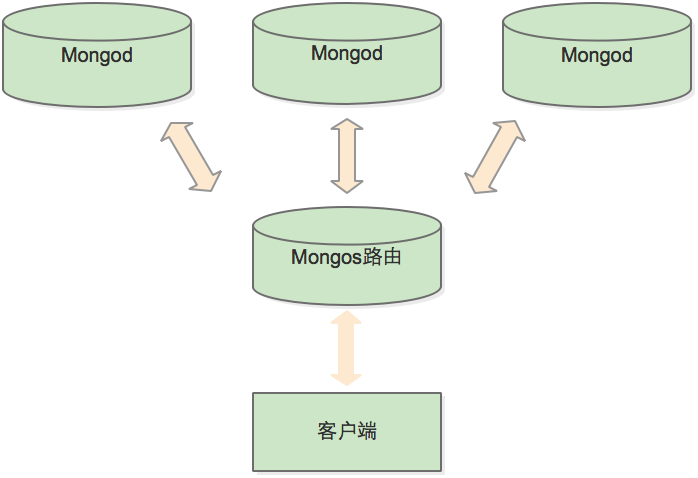
Mongos作为分片集群的访问入口,所有的请求都由mongos来路由、分发、合并,这些动作对客户端驱动透明,用户连接mongos就像连接mongod一样使用,mongos可以是一个或多个,一般部署两个做高可用即可。
Mongos会根据请求类型及片键将请求路由到对应的分片
查询请求
- 查询请求不包含片键,则必须将查询分发到所有的分片,然后合并查询结果返回给客户端
- 查询请求包含片键,则直接根据片键计算出需要查询的块(chunk),向对应的分片发送查询请求
插入请求
写操作必须包含片键,mongos根据片键算出文档应该存储到哪个chunk,然后将写请求发送到chunk所在的分片。
更新/删除请求
更新、删除请求的查询条件必须包含片键或者_id,如果是包含片键,则直接路由到指定的chunk,如果只包含_id,则需将请求发送至所有的分片。
其他命令请求
除增删改查外的其他命令请求处理方式都不尽相同,有各自的处理逻辑,比如listDatabases命令,会向每个分片转发listDatabases请求,然后将结果进行合并。
何时分片
通常,不必太早分片,因为分片不仅会增加部署的复杂度、还要求做出设计决策,而且该决策在以后很难再改。
另外,不能太晚分片,因为在一个过载的系统上不停机进行分片是非常困难的。
分片的目的:
- 增加可用内存空间
- 增加可用磁盘空间
- 减轻单台服务器的负载
- 处理单个MongoDB服务器无法承受的吞吐量
随着不断增加分片的数量,系统性能大致会呈线性增长,但是,如果从一个未分片的系统转换为只有几个分片的系统,性能通常会有所下降。由于迁移数据、维护元数据、路由等开销,少量分片的系统与未分片的系统相比,通常延迟更大,吞吐量甚至更小。一般的,至少应该创建3个或以上的分片。
选择片键
使用分片时,最重要、最困难的任务时选择数据的分发方式。对集合分片时,要选择一个或两个字段用于拆分数据。这个键(或这些键)称为片键。一旦拥有多个分片,再修改片键几乎是不可能的,所以必需在一开始就确定好片键。
最常见的片键有三种:
- 升序片键(ascending key)
- 随机分发的片键(random key)
- 基于位置的片键(location-based key)
升序片键
升序片键有点类似于“data“字段或_id字段,是一种会随着时间稳定增长的字段。
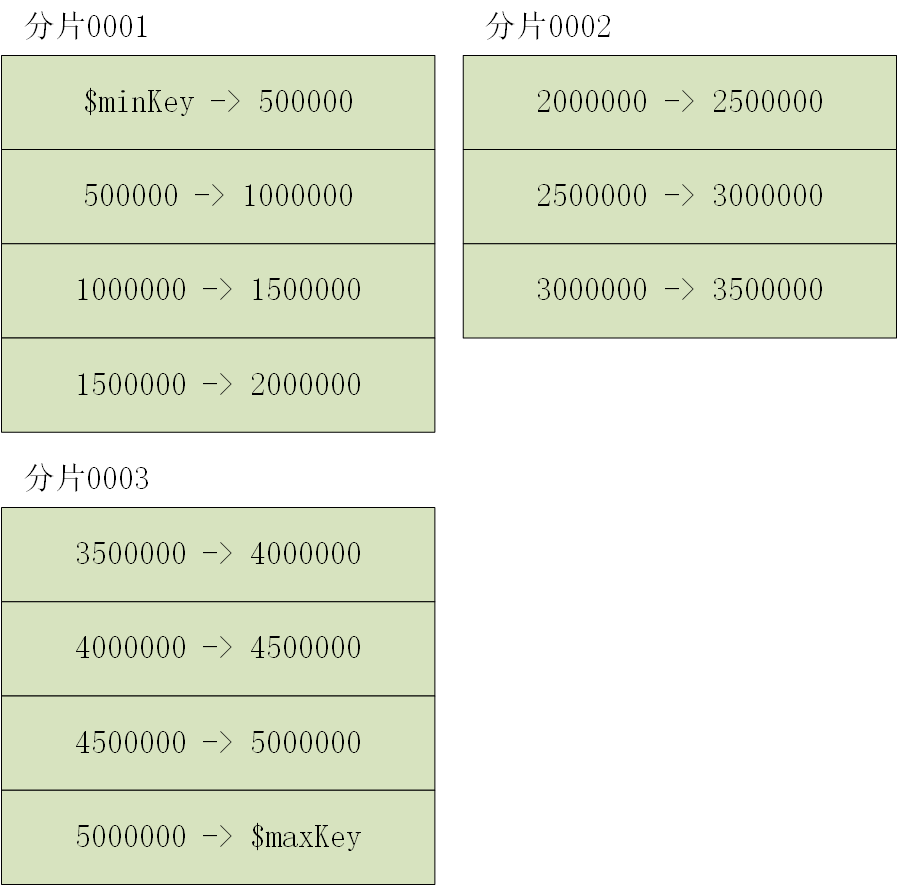
假设已存在一个集合,有5百万条数据,以简化的_id(实际_id是24个16进制字符组成,这里简化便于理解)建立三个分片0001-0003,集合根据_id拆分为多个范围的块,$maxKey指正无穷,5000000->$maxKey是一个最大块。之后插入的数据都会在最大块中,最大块不是无限大的,它会继续拆分成多个小块,不过还是有以下缺点:
- 会导致之后所有的写操作均被路由至分片0003中
- MongoDB必须不断地将一些块从分片0003移动至其他分片。
优点是:很好的满足范围查询的请求,比如想查询范围在2500000~2500010的文档,mongos直接路由至分片0002就能查询出所有符合条件的文档。
随机分发的片键
随机分发的片键可以是用户名、邮件地址、设备id、md5散列值等没有规律的键。
假设片键是0-1之间的随机数,数据的随机性意味着新插入的数据会比较均衡的分发至不同的块中,因此,各分片的增长速度大致相同,这就减少了需要进行迁移的次数。
随机分发片键的缺点:范围查询要分发到后端所有的分片才能找出满足条件的文档

基于位置的片键
片键是用户IP、经纬度、地址等,数据会依据这个位置进行分组,与该位置接近的文档会保存在同一个范围的块中,优点是可以将数据与相关联的用户、相关联的数据保存在一起。
片键策略
好的片键策略应该拥有如下特性:
- key 分布足够离散
- 写请求均匀分布
- 读请求均匀分布,尽量避免 scatter-gather 查询 (所有读请求皆在一个分片上,targeted read)
目前主要支持2种数据分布的策略,范围分片(Range based sharding)或hash分片(Hash based sharding)
- 范围分片的策略的一种实现是升序片键,能很好的满足『范围查询』的需求,缺点在于,如果片键有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个块,无法扩展写的能力。
- Hash分片是根据用户的片键计算hash值(64bit整型),根据hash值按照『范围分片』的策略将文档分布到不同的块。Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的分片才能找出满足条件的文档。
举个例子,某IOT应用使用 MongoDB分片集群存储海量设备(假设100W台)的工作日志,设备每10s向 MongoDB汇报一次日志数据(这个量级,无论从写入还是数据量上看,都应该使用 分片,以便能水平扩张),日志包含deviceId,timestamp信息,应用最常见的查询请求是:查询某个设备某个时间内的日志信息
方案1:使用时间戳作为片键,采用范围分片策略
时间戳是递增的,支持范围分片策略,新的写入都是连续的时间戳,写入请求会集中到同一个分片上,写请求分布不均匀,但是
deviceId不是片键,根据deviceId查询会分散到所有的分片上,效率低下。方案2:使用时间戳作为片键,采用hash分片策略
由于采用了hash分片策略,保证了写请求均匀分布,与方案1一样,
deviceId不是片键,根据deviceId查询会分散到所有的分片上,效率低下。方案3:使用
deviceId作为片键,采用范围分片策略如果deviceId是没有明显规则的,写请求会均匀分布,根据
deviceId的查询均会路由至该分片,查询的要求是某个设备的某个时间段,所以,路由至该分片后,还需要全表扫描并排序,才能找出该设备某时间段内的日志信息。方案4:使用
deviceId作为片键,采用hash分片与方案3
deviceId无规则时基本一致。方案5:使用
deviceId+时间戳作为片键,建立复合索引,采用范围分片策略同一个设备的数据能够根据时间戳进一步分散到多个chunk,根据deviceId查询时间范围的数据,能够利用复合索引来完成,性能是最优的,不过前提是
deviceId无明显规则。